
Unlocking Data Engineering: Simplifying the Journey for Beginners
Data Engineering Essentials


Navigating the vast landscape of Data Engineering tools and concepts can be overwhelming for newcomers, with a multitude of elements to consider: data sources, storage solutions, schemas, formats, pipelines, visualization tools, and processing engines etc
Aspiring Data Engineers, Getting quick wins is crucial for maintaining momentum and motivation!
Inspiration for this newsletter post is from Data Expert Zach Wilson Linkedin Post
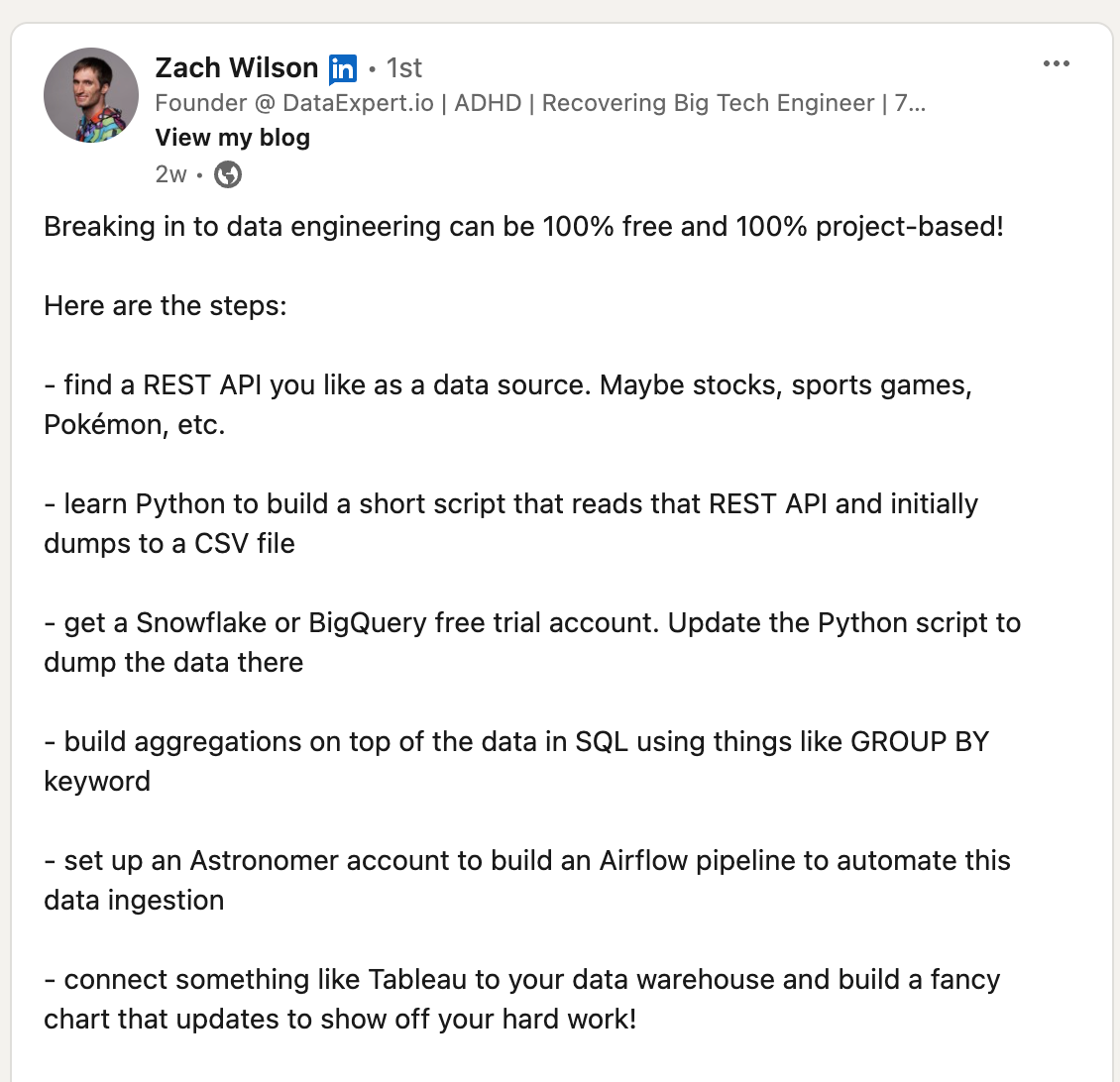
For this newsletter post, I deliberately began with a small dataset and relied solely on Python Pandas to experience the quick win and gain a nutshell understanding of end-to-end data processing.
At any point in time you think you got stuck, feel free to ping me on Linkedin kirankbs!
Let's stroll through this beginner-friendly process to grasp what's going on, and I'll help you navigate through it to achieve a swift victory!
Prerequisites
Please note that this example utilizes MacOS and Python version 3.8.8. However, users on Linux and Windows systems should encounter no issues!
Set Up Python Project
Download or Clone source code from GitHub Repository. You can open following project any IDE such as IntelliJ/PyCharm, VSCode or simply Text Editor.

Let’s create a Python virtual environment to install project dependencies locally. Run the below commands inside the project folder
python -m venv venvActivate Python Virtual environment
source venv/bin/activateInstall Dependencies
pip install -r requirements.txtNow, the project is downloaded and dependencies are installed!
However, you'll still need to set up a Snowflake account and configure the project before running the application.
Snowflake Set Up
Snowflake Cloud offers a 30-day free trial, providing ample time to explore and gain practical experience. Once you've signed up and created an account, you should configure the code block mentioned below inside the file WriteToSnowflake.py
conn_params = {
'account': 'account name', # Replace with your account name
'user': 'user name', # Replace with your username
'password': 'password', # Replace with your password
'warehouse': 'NYCTAXI',
'database': 'NYCTAXIDATABASE',
'schema': 'public'
}with the following details:
Account: This serves as the unique identifier for your Snowflake account. You typically receive it upon signing up for Snowflake. You can also find it in the URL you use to access the Snowflake web interface. For instance, if the URL is https://app.snowflake.com/lzkqavc/dq12000, the account name would be lzkqavc-dq12000. Alternatively, you can locate it under Admin → Accounts, resembling https://<account>.snowflakecomputing.com.

User: This is the username you use to log in to Snowflake.
Password: This is the password associated with your Snowflake user account.

Warehouse: In Snowflake, a warehouse is a computing resource that executes SQL queries. Create a new warehouse NYCTAXI by navigating to the Admin -> Warehouses tab.

Database: A database in Snowflake is a container for your data and database objects. Create a new database NYCTAXIDATABASE by logging in to Snowflake and navigating to the Data → Databases tab.

Schema: A schema in Snowflake is a logical container for database objects, such as tables, views, and functions. You can find the available schemas by logging in to Snowflake and selecting the desired database. public schema is the default schema in Snowflake.

Create table Table inside the public schema with the following definition
create or replace TABLE NYCTAXIDATABASE.PUBLIC.TRIPS (
VENDORID VARCHAR(16777216),
LPEP_PICKUP_DATETIME VARCHAR(16777216),
LPEP_DROPOFF_DATETIME VARCHAR(16777216),
STORE_AND_FWD_FLAG VARCHAR(16777216),
RATECODEID VARCHAR(16777216),
PICKUP_LONGITUDE NUMBER(38,0),
PICKUP_LATITUDE NUMBER(38,0),
DROPOFF_LONGITUDE NUMBER(38,0),
DROPOFF_LATITUDE NUMBER(38,0),
PASSENGER_COUNT NUMBER(38,0),
TRIP_DISTANCE NUMBER(38,0),
FARE_AMOUNT NUMBER(38,0),
EXTRA NUMBER(38,0),
MTA_TAX NUMBER(38,0),
TIP_AMOUNT NUMBER(38,0),
TOLLS_AMOUNT NUMBER(38,0),
IMP_SURCHARGE NUMBER(38,0),
TOTAL_AMOUNT NUMBER(38,0),
PAYMENT_TYPE VARCHAR(16777216),
TRIP_TYPE VARCHAR(16777216)
);Run the Application
As the code is pretty self-explanatory, let’s run the below commands inside the project folder
python src/nyc-taxi-data-e2e/WriteToSnowflake.pyYou will find the following result
in Console

Click Refresh button at Data → Databases → NYCTAXIDATABASE → public → Tables → TRIPS → Data Preview. Tada! There you go with the Data!

Congratulations, If you have come across this far!
This is it! It is this simple to fetch data from API and insert it into the Snowflake Database. You don’t need Spark, Flink, or Notebook .. to write simple code.
Note: This application is far fetch from completion but let’s take basic steps and improve this application further!
Please subscribe for more such content and share for the far reach!
very interesting Kiran, there is everything you need to emulate the project!